Last month I set out to make what felt like a fairly straightforward change. I wanted to switch “Execute All Queries” from running each query in parallel, to running the queries serially as one SQL script. Unfortunately, it didn’t quite end up being the simple change I expected. After a lot of testing (and maybe a few tears 😢), I’m happy to announce that you can now run SQL scripts in modelDBA! More details below.
Download the latest version of modelDBA here. This release includes the following upgrades.
Major
SQL Scripts
When running queries using “Execute All Queries”, the queries are now run serially as a single script, instead of in parallel. Previously, it was impossible to enforce the specific order that queries ran in without running each one manually.
As before, rows are still fetched 100 at a time. If your result set has more than 100 rows the remaining queries will be paused until you have retrieved all rows. Additional rows are automatically retrieved when you scroll to the bottom of the results table, or by right-clicking on the result tab and clicking “Load Next 100 Rows”.
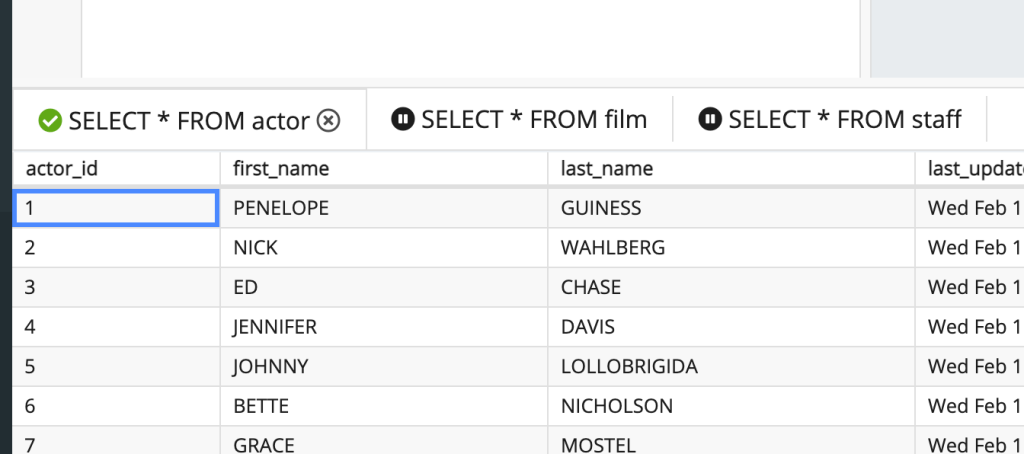
View Batch
If a query has not yet been run, or a previous query has an error, you can see which result tabs are part of the same batch by hovering over the batch keyword.

Failed Queries
If one of the queries in your script fails, all subsequent queries will not be run. The error icon will show which query failed, and the empty circle icon will show which queries were never run.

Minor
- Close result tab icon is now clickable when not focused on the same tab (thanks for the bug report, Sebastian!).
- Fixed displaying the number of affected rows for INSERT/UPDATE/DELETE statements for PostgreSQL and SQL Server databases.
- Fixed displaying output columns when using functions in the SELECT list for SQL Server.
Do you have a feature request for modelDBA? Found a bug 😬? Let me know at [email protected]. Your feedback makes modelDBA better for everyone.
You can get the latest version of modelDBA here. Or, just open up modelDBA on your machine and you’ll be prompted to upgrade.